如何将任何文本转换为图谱?

使用 Mistral 7B 将任何文本语料库转换为知识图的方法

此图由作者使用本文分享的项目生成。几个月前,基于知识的问答(KBQA)还只是新奇事物。如今,对于任何人工智能爱好者来说,使用检索增强生成(RAG)实现KBQA已经轻而易举。看到自然语言处理领域的可能性如此迅速地扩展,令人着迷,而且每天都在变得更好。在我的最后一篇文章中,我分享了一种递归的RAG方法,用于根据大量文本语料库回答复杂查询的多跳推理式问答实现。
研究代理:应对基于大型文本语料库回答问题的挑战
我制作了一个能够通过深度多跳推理能力回答困难问题的自主人工智能研究代理
很多人尝试了它并发送了他们的反馈。感谢大家的反馈。我已经整理了这些贡献并对代码进行了一些改进,以解决原始实现中的一些问题。我计划写一篇独立的文章关于这个。在这篇文章中,我想分享另一个想法,当与递归RAG结合使用时可能有助于创造一个超级研究代理。这个想法是根据我对较小LLMs进行递归RAG实验以及我在Medium上阅读到的一些其他想法的结合产生的,特别是其中一个是知识图增强生成。
摘要
一个知识图谱(Knowledge Graphs,KG),或者任何图形,由节点和边组成。KG的每个节点代表一个概念,而每条边则是两个概念之间的关系。在本文中,我将分享一种将任何文本语料库转化为概念图(Graph of Concepts,GC)的方法。我在这里使用术语“概念图”(Graph of Concept)和KG来互换使用,以更好地描述我在这里进行的演示。我在这个实现中使用的所有组件都可以在本地设置,所以这个项目可以在个人机器上轻松运行。我在这里采用了无GPT方法,因为我相信较小的开源模型。我正在使用极好的Mistral 7B Openorca instruct和Zephyr模型。这些模型可以在Ollama上在本地设置。
像Neo4j这样的数据库使得存储和检索图数据变得容易。在这里,我使用内存中的Pandas Dataframes和NetworkX Python库来保持简单。我们在这里的目标是将任何文本语料库转化为概念图(GC),并像本文的美丽横幅图像那样进行可视化。我们甚至可以通过移动节点和边缘,缩放和更改图形的物理性质来与网络图进行互动。这是 Github 页面链接,显示了我们正在构建的结果。https://rahulnyk.github.io/knowledge_graph/ 但首先,让我们深入了解知识图谱的基本概念以及为什么我们需要它们。如果你已经熟悉这个概念,可以跳过下一节。
知识图谱
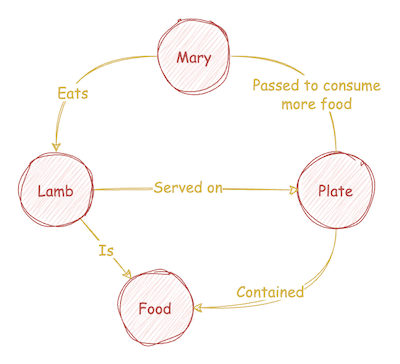
请考虑以下文本。
- 玛丽有一只小羊,
- 你之前听过这个故事;
- 但你知道她经过一番餐盘,
- 还有一点点!
下面是将文本表示为知识图的一种可能形式。
以下IBM的文章恰当解释了知识图的基本概念。
知识图是什么?
了解知识图谱,语义元数据网络代表一系列相关实体的集合。
引用文章摘录总结思想:
知识图谱,也被称为语义网络,代表了一个由实际世界中的实体(例如对象、事件、情况或概念)构成的网络,并且展示了它们之间的关系。这些信息通常存储在图形数据库中,并可视化为图形结构,因此得名知识“图谱”。
为何使用知识图谱?
知识图谱在各种情况下都非常有用。我们可以运行图算法并计算任何节点的中心性,以了解一个概念(节点)对整个工作体系的重要性。我们可以分析连接和断开的概念集合,或计算概念的社群,以深入理解主题内容。我们可以理解看似不相关的概念之间的链接。我们还可以使用知识图谱来实现图检索增强生成(GRAG or GAG)并与我们的文档进行聊天。这比简单的RAG旧版本可以给我们更好的结果,而RAG旧版本存在一些缺点。例如,使用简单的语义相似性搜索来检索与查询最相关的上下文并不总是有效的。特别是当查询没有提供足够的关于其真实意图的上下文,或者当上下文零散分布在一个大型文本语料库中时。
例如,考虑这个查询:
告诉我一下《百年孤独》中何塞·阿卡迪奥·布恩迪亚的家族谱系。
这本书记录了七代的何塞·阿卡迪奥·布恩迪亚,其中一半的角色都被命名为何塞·阿卡迪奥·布恩迪亚。如果只使用简单的RAG流程,回答这个问题将是相当具有挑战性的,甚至可能是不可能的。RAG的另一个缺点是它无法告诉你应该问什么。很多时候,提出正确的问题比获取答案更重要。图增强生成(GAG)可以在一定程度上解决RAG的这些缺点。更好的是,我们可以混合搭配,构建一个图增强检索增强生成的流程,以获得两者的最佳效果。因此,现在我们知道图是有趣的,它们可以极其有用,而且它们看起来也很美丽。
创建概念图
如果你问GPT,如何从给定的文本中创建知识图谱?它可能会建议以下类似的过程。
- 从作品中提取概念和实体。这些是节点。
- 提取概念之间的关系。这些是边。
- 将节点(概念)和边(关系)填充到图形数据结构或图形数据库中。
- 可视化,为了艺术上的愉悦,或其他目的。
步骤3和4听起来容易理解。但是如何实现步骤1和2呢?这是我设计的从任何给定文本语料库中提取概念图的方法的流程图。它与上述方法类似,但也有些许不同之处。
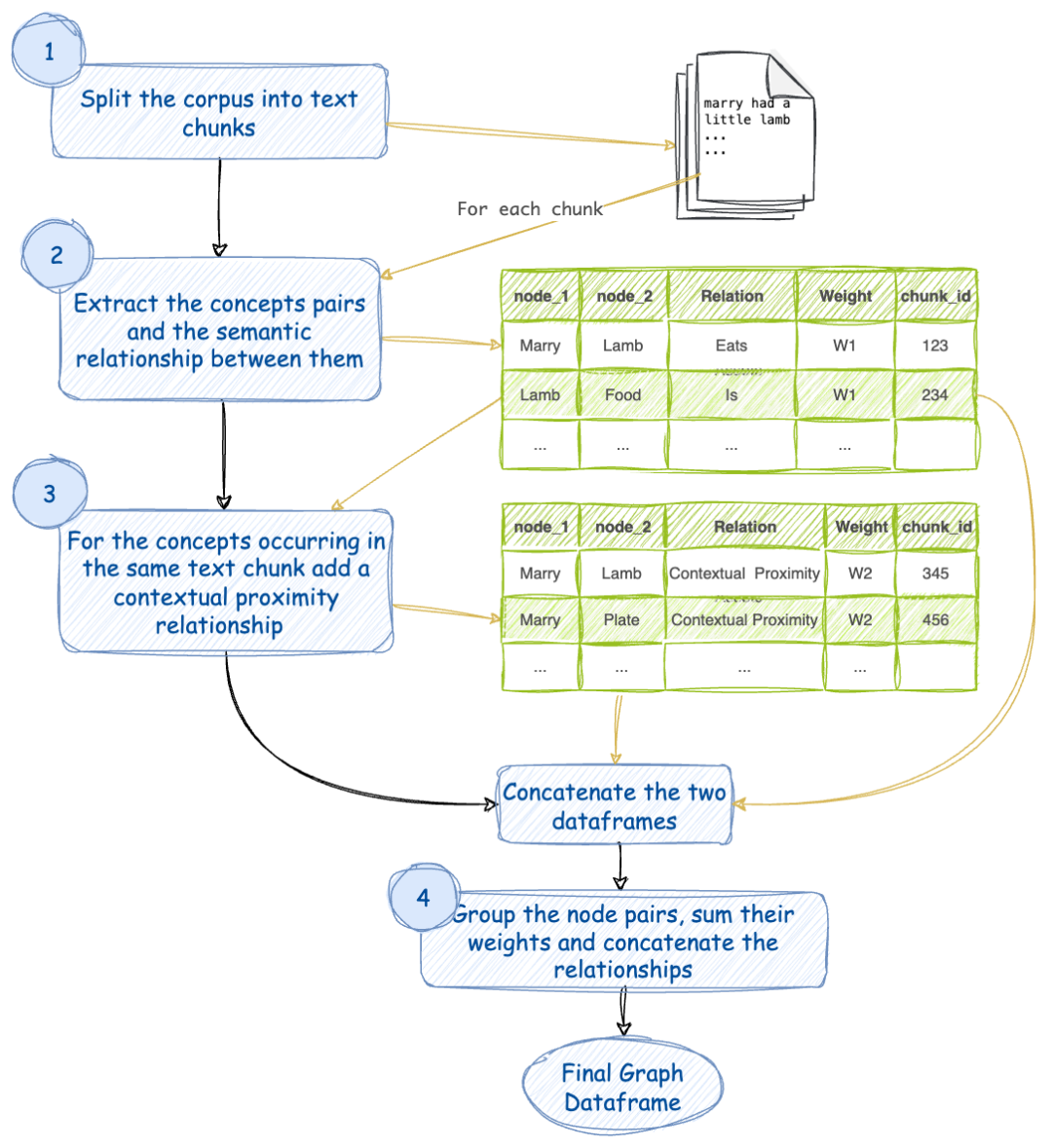
图表由作者使用draw.io创建
- 将文本语料库拆分为块。为每个块分配一个块标识符(chunk_id)。
- 对于每个文本块,使用一个LLM提取概念及其语义关系。让我们给这个关系赋予权重W1。同一对概念之间可能存在多种关系。每种关系都是一对概念之间的边。
- 考虑到出现在同一文本块中的概念也通过上下文的接近性相互关联。让我们给这个关系赋予权重W2。注意,同一对概念可能在多个块中出现。
- 将相似的概念对进行分组,求和它们的权重,并连接它们的关系。这样,任意不同的概念对之间只有一条边。该边拥有一定的权重和一串关系作为其名称。你可以在我在本文中分享的GitHub存储库中看到此方法的Python代码实现。让我们在接下来的几个部分简要介绍实现的关键思想。
在这里,我将使用在PubMed/Cureus上发表的以下评论文章来演示该方法,根据创作共用许可证给予作者以信誉。在本文末尾致谢作者。
印度面对医疗人力资源挑战的机会
印度的健康指标近年来有所改善,但仍落后于其同行国家。…
风和提示
上述流程图中的第一步很简单。Langchain提供了许多文本分割工具,我们可以使用它们将文本分割成块。第二步是真正有趣的开始。为了提取概念及其关系,我使用了Mistral 7B模型。在确定最适合我们目的的模型变体之前,我尝试了以下模型: Mistral Instruct[1] Mistral OpenOrca[2],和 Zephyr (基于Mistral的Hugging Face版本)[3] 我使用了这些模型的4位量化版本,这样我的Mac就不会讨厌我了,这些模型托管在Ollama本地。
Ollama
在本地使用大型语言模型。
ollama.ai[4] 这些模型都是经过指令调整的模型,包括一个系统提示和一个用户提示。如果我们告诉它们的话,它们都可以很好地按照指示执行,并将答案整洁地格式化为JSON。经过几轮尝试,我最终选择了以下提示来使用Zephyr模型。
SYS_PROMPT = (
"您是一个网络图形制作者,可以从给定的语境中提取术语及其关系。"
"您会被提供一个语境块(由```分隔)。您的任务是提取给定语境中提及的术语的本体论。这些术语应该代表语境中的关键概念。\n"
"思考1:在遍历每个句子时,思考其中提及的关键术语。\n"
"\t术语可能包括对象、实体、位置、组织、人员、\n"
"\t条件、缩写、文档、服务、概念等。\n"
"\t术语应尽可能具有原子性。\n\n"
"思考2:思考这些术语如何与其他术语之间存在一对一关系。\n"
"\t在同一句子或段落中提及的术语通常彼此相关。\n"
"\t术语可以与许多其他术语相关联。\n\n"
"思考3:找出每对相关术语之间的关系。\n\n"
"将输出格式化为一组json对象列表。列表的每个元素包含一对术语"
"及其之间的关系,示例如下:\n"
"[\n"
" {\n"
' "node_1": "从提取的本体论中的一个概念",\n'
' "node_2": "从提取的本体论中的一个相关概念",\n'
' "edge": "两个概念node_1和node_2之间的关系,在一两个句子中说明"\n'
" }, {...}\n"
"]"
)
USER_PROMPT = f"上下文: ```{input}``` \n\n 输出: "
如果我们使用这个提示传递我们的提示词,这就是结果。
[
{
"节点_1": "Mary",
"节点_2": "lamb",
"关系": "属于"
},
{
"节点_1": "plate",
"节点_2": "food",
"关系": "包含"
}, . . .
]
请注意,它甚至猜到了’food’作为一个概念,这在文本片段中并没有明确提到。这不是很棒吗!
如果我们将这个通过示例文章的每个文本片段,并将json转换为Pandas数据框,结果如下。

这里每一行代表两个概念之间的关系。每一行都是我们图中两个节点之间的边,同一对概念之间可以有多条边或者多种关系。上述数据框中的计数是我任意设置的权重为4。
上下文接近性
我假设在文本语料库中出现在彼此附近的概念是相关的。让我们称这种关系为’上下文接近性’。要计算上下文接近性边,我们先融合数据框,使得node_1和node_2合并成一列。然后,我们使用chunk_id作为键对该数据框进行自连接。这样,具有相同chunk_id的节点将配对成一行。但这也意味着每个概念也将与其自身配对。这被称为自循环,即边从一个节点开始并结束于同一节点。为了删除这些自循环,我们将在数据框中删除所有node_1等于node_2的行。最后,我们得到了一个与原始数据框非常相似的数据框。

这里的count列是node_1和node_2一起出现的块数。chunk_id列是所有这些块的列表。所以现在我们有两个数据框,一个是语义关系,另一个是文本中提到的概念之间的上下文接近关系。我们可以将它们合并到一起形成我们的网络图数据框。我们已经构建了一个文本概念图。但是仅仅在这一点上停止将是一个相当令人失望的过程。我们的目标是像本文开头的特色图片一样将图形可视化,离实现目标并不遥远。
创建概念网络
NetworkX是一个使处理图形变得非常简单的Python库。如果您还不熟悉这个库,点击下面的标志了解更多信息。
NetworkX – NetworkX文档
NetworkX是一个用于创建、操作和研究网络结构、动态和功能的Python包。将我们的数据帧添加到NetworkX图中只需几行代码。
G = nx.Graph()
添加节点到图中
for node in nodes: G.add_node(str(node))
添加边到图中
for index, row in dfg.iterrows(): G.add_edge( str(row["node_1"]), str(row["node_2"]), title=row["edge"], weight=row['count'] )
这就是我们可以开始利用网络图的力量的地方。NetworkX为我们提供了众多的网络算法,供我们直接使用。这里有一个链接,指向我们可以在我们的图上运行的算法列表。
算法 – NetworkX 3.2.1 文档
修改描述
networkx.org[5] 在这里,我使用社区检测算法给节点添加颜色。社区是指那些彼此之间连接更紧密的节点群体,而不是图中其他部分。概念的社区能为我们提供关于文本中讨论的广泛主题的很好的想法。Girvan Newman算法在我们所研究的评论文章中检测到了17个概念的社区。这是其中一个社区。[ ‘数字技术’, ‘EVIN’, ‘医疗设备’, ‘在线培训管理信息系统’, ‘可穿戴、可追踪技术’ ] 这立即给我们一个关于回顾文章中讨论的健康技术领域的广泛主题的想法,并使我们能够提出问题,然后用我们的RAG Pipeline来回答。这不是很棒吗?让我们还计算一下图中每个概念的度。节点的度是它连接的边的总数。所以在我们的案例中,一个概念的度越高,它就越是与我们文本主题相关的核心。我们将使用度作为节点在我们的可视化中的大小。
图可视化
可视化是这个练习中最有趣的部分。它具有一定的质感,给你带来艺术上的满足。我正在使用PiVis库来创建交互式图形。Pyvis是一个用于可视化网络的Python库[6]。这是一篇展示该库简易性和强大性的中文文章。
Pyvis: 使用Python可视化交互式网络图
需要的只是几行代码
Pyvis具有内置的NetworkX Helper,可以将我们的NetworkX图转换为PyVis对象。所以我们不需要编写更多的代码…耶!!记住,我们已经计算出了每条边的权重来确定边的粗细,每个节点的社区来确定它们的颜色,以及每个节点的度来确定它们的大小。因此,有了所有这些花里胡哨的东西,这是我们的图。
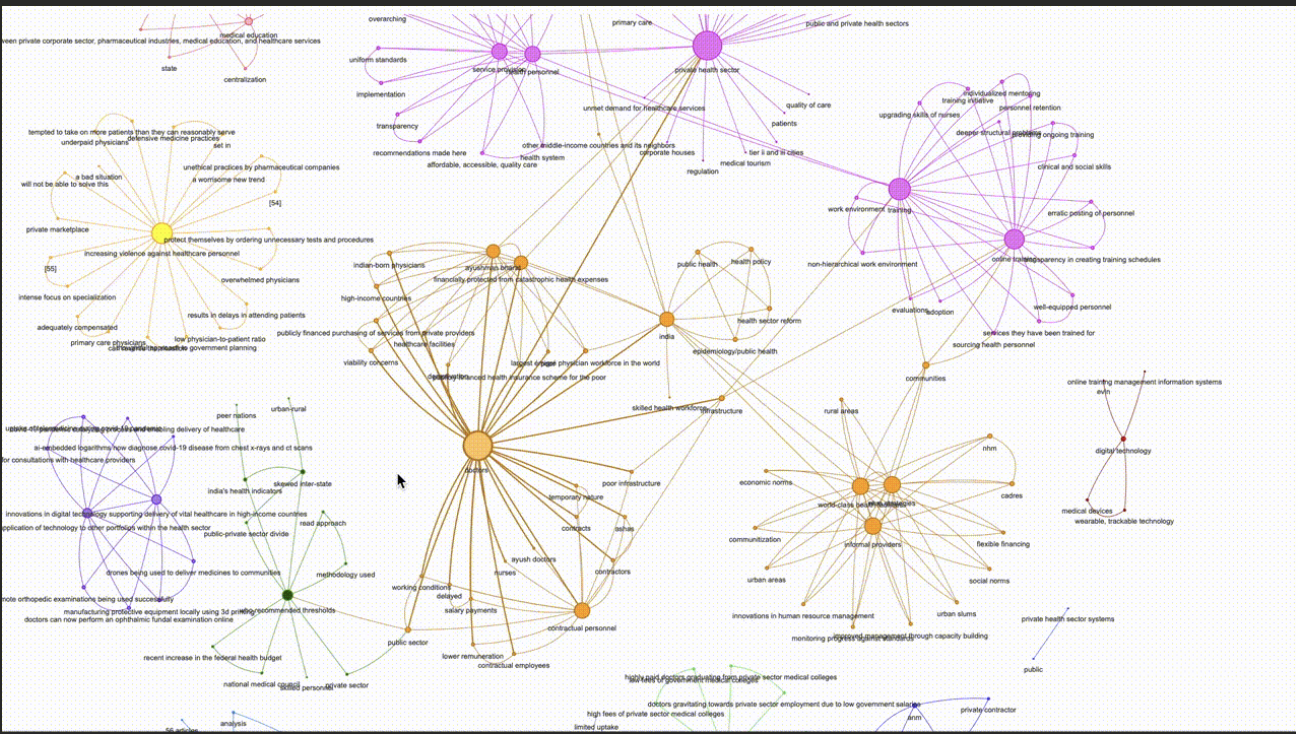
这个图由作者使用本文讨论的项目生成。交互图的链接: https://rahulnyk.github.io/knowledge_graph/ 我们可以根据需求放大、缩小和移动节点和边。我们还可以通过页面底部的滑块面板来改变图表物理属性。看看这个图表如何帮助我们提出正确的问题和更好地理解主题!我们可以进一步讨论我们的图表如何帮助我们构建图增强检索以及如何帮助我们构建更好的RAG管道。但我认为最好留待以后再讨论。我们已经实现了本文的目标!
GitHub仓库
References
[1] Mistral Instruct: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
[2] Mistral OpenOrca: https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca
[3] Zephyr (基于Mistral的Hugging Face版本): https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
[4] ollama.ai: https://ollama.ai/?source=post_page—–110844f22a1a——————————–
[5] networkx.org: https://networkx.org/documentation/stable/reference/algorithms/index.html?source=post_page—–110844f22a1a——————————–
[6] Pyvis是一个用于可视化网络的Python库: https://github.com/WestHealth/pyvis/tree/master#pyvis—a-python-library-for-visualizing-networks